大数据系列(3)-HDFS 常用命令
目录
本文基于之前搭建的集群,通过服务端以及客户端对HDFS的操作,让大家熟悉HDFS的使用。
命令都很简单,基本就是Linux操作命令
[hadoop@leader hadoop]$ hadoop fs -help Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum [-v] <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-concat <target path> <src path> <src path> ...] [-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>] [-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] [-s] <path> ...] [-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] [-v] [-x] <path> ...] [-expunge [-immediate] [-fs <path>]] [-find <path> ... <expression> ...] [-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getfattr [-R] {-n name | -d} [-e en] <path>] [-getmerge [-nl] [-skip-empty-file] <src> <localdst>] [-head <file>] [-help [cmd ...]] [-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]] [-mkdir [-p] <path> ...] [-moveFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>] [-moveToLocal <src> <localdst>] [-mv <src> ... <dst>] [-put [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>] [-renameSnapshot <snapshotDir> <oldName> <newName>] [-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...] [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setfattr {-n name [-v value] | -x name} <path>] [-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] [-s <sleep interval>] <file>] [-test -[defswrz] <path>] [-text [-ignoreCrc] <src> ...] [-touch [-a] [-m] [-t TIMESTAMP (yyyyMMdd:HHmmss) ] [-c] <path> ...] [-touchz <path> ...] [-truncate [-w] <length> <path> ...] [-usage [cmd ...]]重点说明以下命令:
1.1 appendToFile 追加到文件
可以看到文件被追加到fs /input/wcinput_sample.txt
[hadoop@leader hadoop]$ hadoop fs -appendToFile /opt/module/hadoop-3.3.1/wcinput/wcinput_sample.txt /input/wcinput_sample.txt [hadoop@leader hadoop]$ hadoop fs -cat /input/wcinput_sample.txt angus test sufiyar test angus test sufiyar test angus test sufiyar test angus test sufiyar test angus test sufiyar test doudou test hadoop test root tes angus test sufiyar test angus test sufiyar test angus test sufiyar test angus test sufiyar test angus test sufiyar test doudou test hadoop test root tes1.2 copyFromLocal 从本地拷贝
等同于之前使用的-put ,类似命令 moveFromLocal 是从本地剪切到hdfs.
[hadoop@leader hadoop]$ hadoop fs -copyFromLocal /opt/module/hadoop-3.3.1/sbin/angus-hadoop.sh /input [hadoop@leader hadoop]$ hadoop fs -ls /input Found 2 items -rw-r--r-- 3 hadoop supergroup 991 2022-02-08 16:11 /input/angus-hadoop.sh -rw-r--r-- 3 hadoop supergroup 306 2022-02-08 16:06 /input/wcinput_sample.txt1.3 copyToLocal 下载文件到本地
类似的命令moveToLocal 是把hdfs上的剪切到本地
[hadoop@leader hadoop]$ hadoop fs -copyToLocal /input/angus-hadoop.sh ~ [hadoop@leader hadoop]$ ls ~ angus-hadoop.sh1.4 count 统计文件目录、文件数量以及文件总大小
[hadoop@leader hadoop]$ hadoop fs -count /input 1 2 1297 /input [hadoop@leader hadoop]$ hadoop fs -ls /input Found 2 items -rw-r--r-- 3 hadoop supergroup 991 2022-02-08 16:11 /input/angus-hadoop.sh -rw-r--r-- 3 hadoop supergroup 306 2022-02-08 16:06 /input/wcinput_sample.txt1.5 getmerge 合并文件
把多个文件merge到一个文件,如下列,把/input 的文件merge后,保存在本地用户目录的mergeOne.txt中。
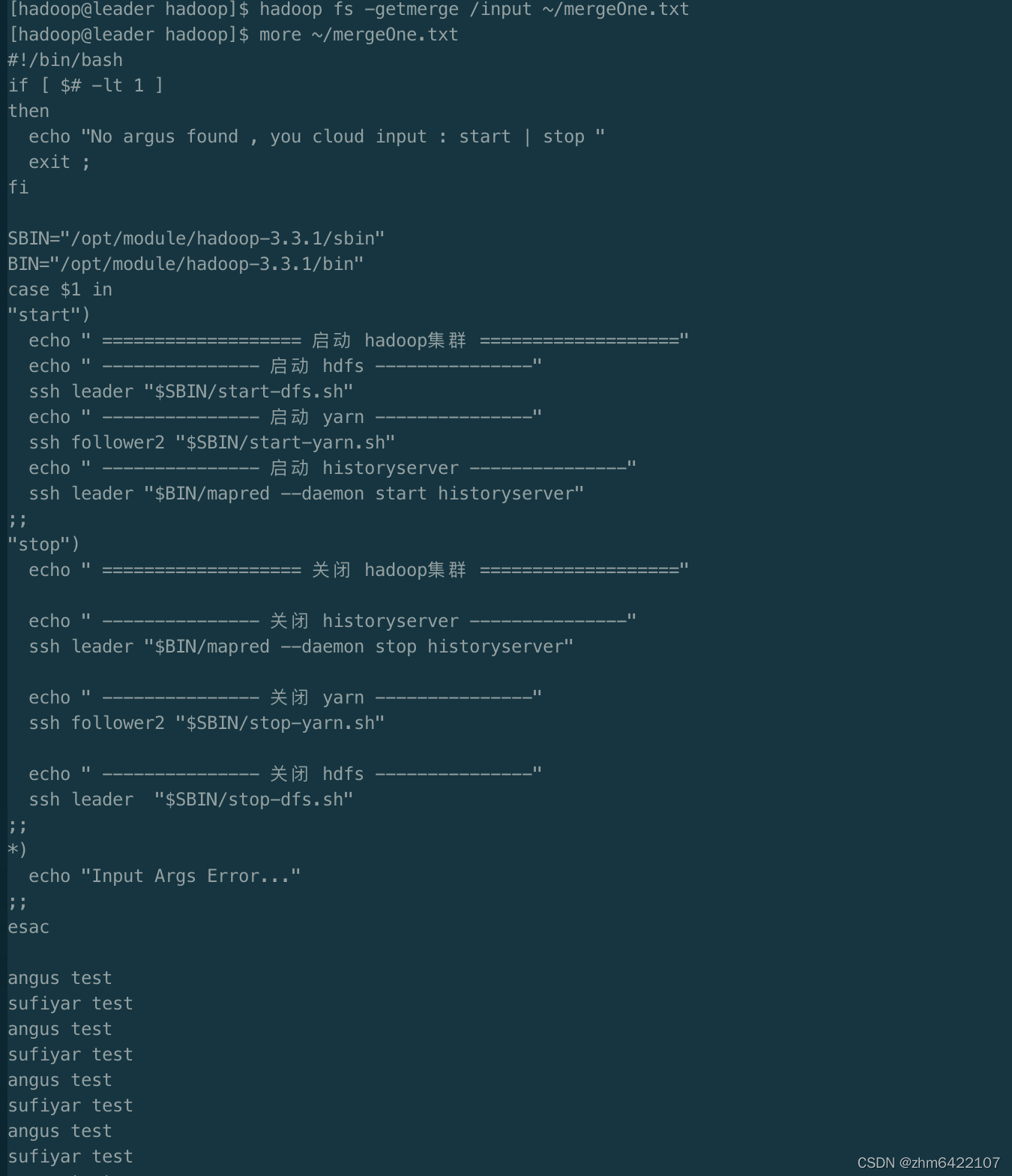
1.6 必杀技
hadoop fs -help XX (XX为你想了解的命令)
使用场景比较少,暂时不深入,试点几个操作
2.1 新建Java工程,添加依赖包:
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.1</version> </dependency>2.2 Java代码
package com.angus.hadoop.hdfs; import lombok.extern.log4j.Log4j2; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.LocatedFileStatus; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.RemoteIterator; import org.junit.jupiter.api.AfterAll; import org.junit.jupiter.api.BeforeAll; import org.junit.jupiter.api.Test; import java.io.File; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import java.util.Arrays; /** * Created with p4j. * User: anguszhu * Date: 2月,10 2022 * Time: 下午4:35 * description: */ @Log4j2 public class HdfsOperationTest { private static FileSystem fs; @BeforeAll public static void initFs(){ try { Configuration conf = new Configuration(); //副本数设置为2 conf.set("dfs.replication", "2"); fs=FileSystem.newInstance(new URI("hdfs://leader:9820"), conf,"hadoop"); } catch (IOException | InterruptedException| URISyntaxException e) { log.error("init failed",e); } } @Test public void testCrateFileWithFS(){ try { Path fspath = new Path("/output"); RemoteIterator<LocatedFileStatus> fileIter = fs.listFiles(fspath, false); printFileInfo(fileIter); fs.copyToLocalFile(new Path("/output/part-r-00000"),new Path("/opt/tech")); File file = new File("/opt/tech/part-r-00000"); log.info("file len:{}",file.length()); fs.copyFromLocalFile(new Path("/opt/tech/part-r-00000"),new Path("/JavaUpload")); fs.deleteOnExit(new Path("/JavaUpload")); RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fs.listFiles(new Path("/JavaUpload"), false); printFileInfo(locatedFileStatusRemoteIterator); } catch (IOException e) { e.printStackTrace(); } } private void printFileInfo(RemoteIterator<LocatedFileStatus> fileIter) throws IOException { while (fileIter.hasNext()) { LocatedFileStatus lfs = fileIter.next(); //输出文件名称 log.info("=========================file Name:{}", lfs.getPath().getName() + "========================="); //获取文件大小,以及文件副本数 log.info("file length={},replications={}", lfs.getLen(), "" + lfs.getReplication()); //记录文件所在节点位置 Arrays.stream(lfs.getBlockLocations()).forEach(l -> log.info(l.toString())); } } @AfterAll public static void closeResouce(){ try { fs.close(); } catch (IOException e) { log.error("close failed",e); } } } 2.3 验证结果
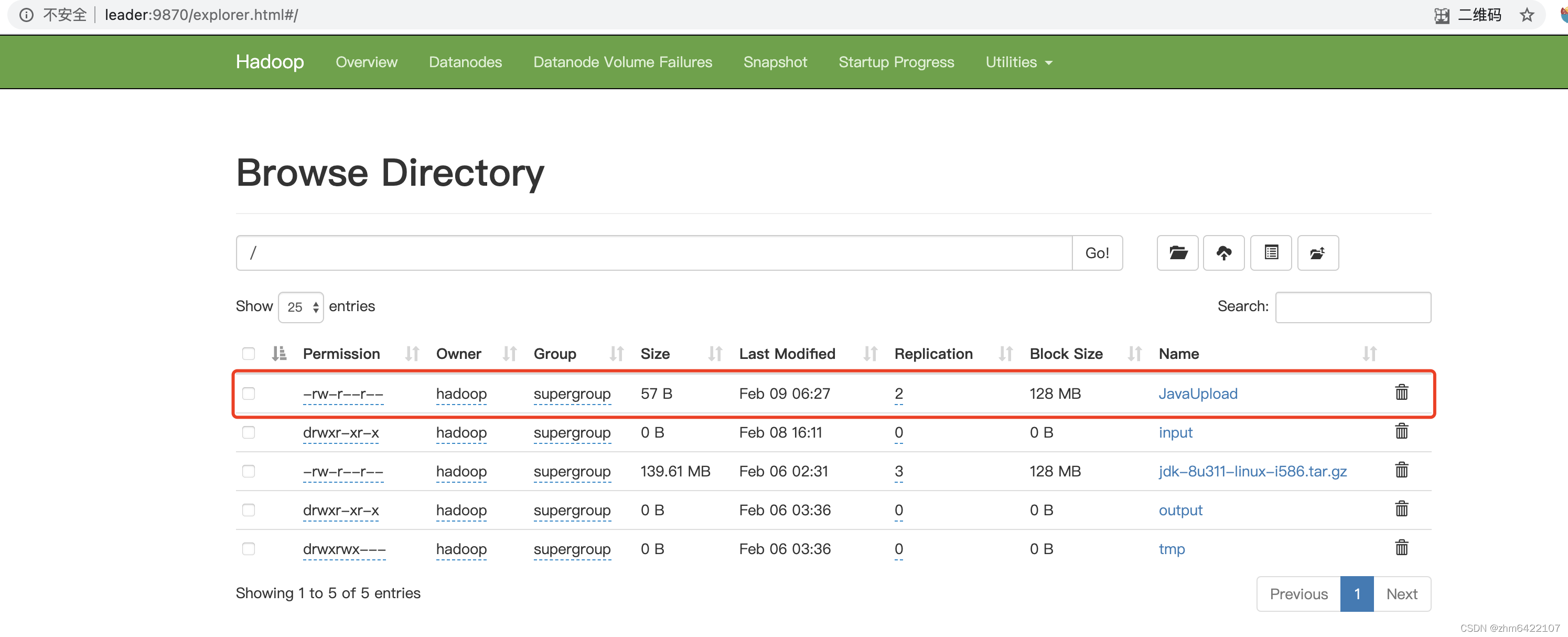
关键日志:

副本数为前面设置的2,文件落在leader,follower2节点,文件大小与之前下载的一样
 浏览器查看一下
浏览器查看一下
l